Table of contents
Contents:
Overview
MILK is a tool that aims to address the rapid growth of high-dimensional data in biology and other fields. It is a recursive, distance-based method designed to capture the complete hierarchy of pairwise relationships between objects in a population in (amortized) linear computing time.
It aims to be versatile in use cases: either by supporting tractable application of existing analytical tools (e.g., generating information-rich subsamples) or by providing a data structure to faciltate diverse downstream analyses.
MILK was developed with the following features in mind:
Scalability: it is an out-of-core algorithm that is tractable in the context of increasingly large-scale datasets (i.e., dataset scales on the order of tens to hundreds of millions of observations). It was implemented in a Julia, a high-performance programming language, and its implementation leverages distributed computing, as well as node clusters in high performance computing (HPC) environments.
Generalizability: recursive application of a data-driven threshold identifies and progressively merges highly-similar objects into groups. The threshold that defines similarity is a percentile on the lower extreme distribution of pairwise comparisons (e.g., 0.01st percentile), which is based on any user-specified pairwise comparison metric. As such, there is minimal parameter tuning, which should translate to reliable “out-of-the-box” performance.
Interpretability: access to comprehensive pairwise similarity comparisons contextualizes how meaningful measured effects are globally. Furthermore, the tree structure provides a simple but principled data structure for explaining observations.
Multi-resolution: the recursive process produces a hierarchical data structure at the resolution of individual objects. This granularity facilitates analyses investigating signal across resolutions; for example, multi-scale organization of biological systems.
Method description
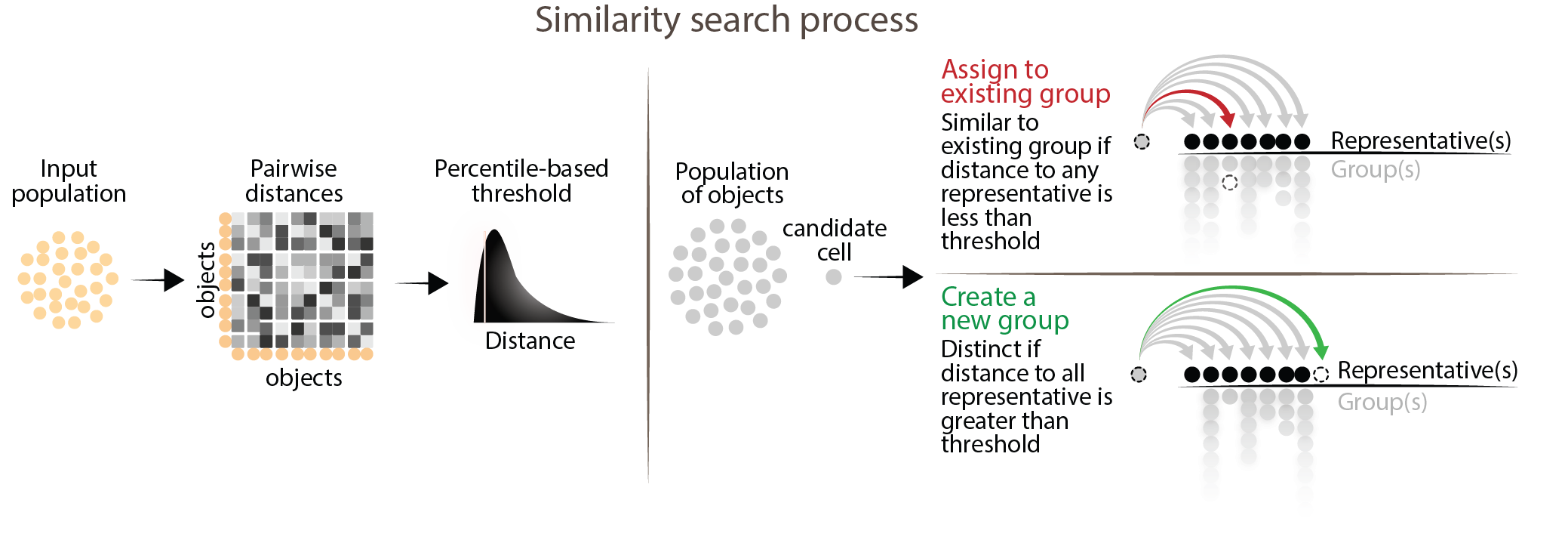
The main process of MILK involves grouping highly similar objects using a data-driven similarity threshold defined by a lower-extreme tail percentile (e.g., 0.01st) of distances. In a single-pass through the dataset, each candidate object is compared to the representatives of existing groups. If the candidate has a distance below the threshold to any group, it is mapped to the group it is most similar to. Conversely, if its distance is greater than the threshold to all existing groups, it is considered distinct, in which case it forms a new group and becomes its representative. The first candidate object forms a new group by default.
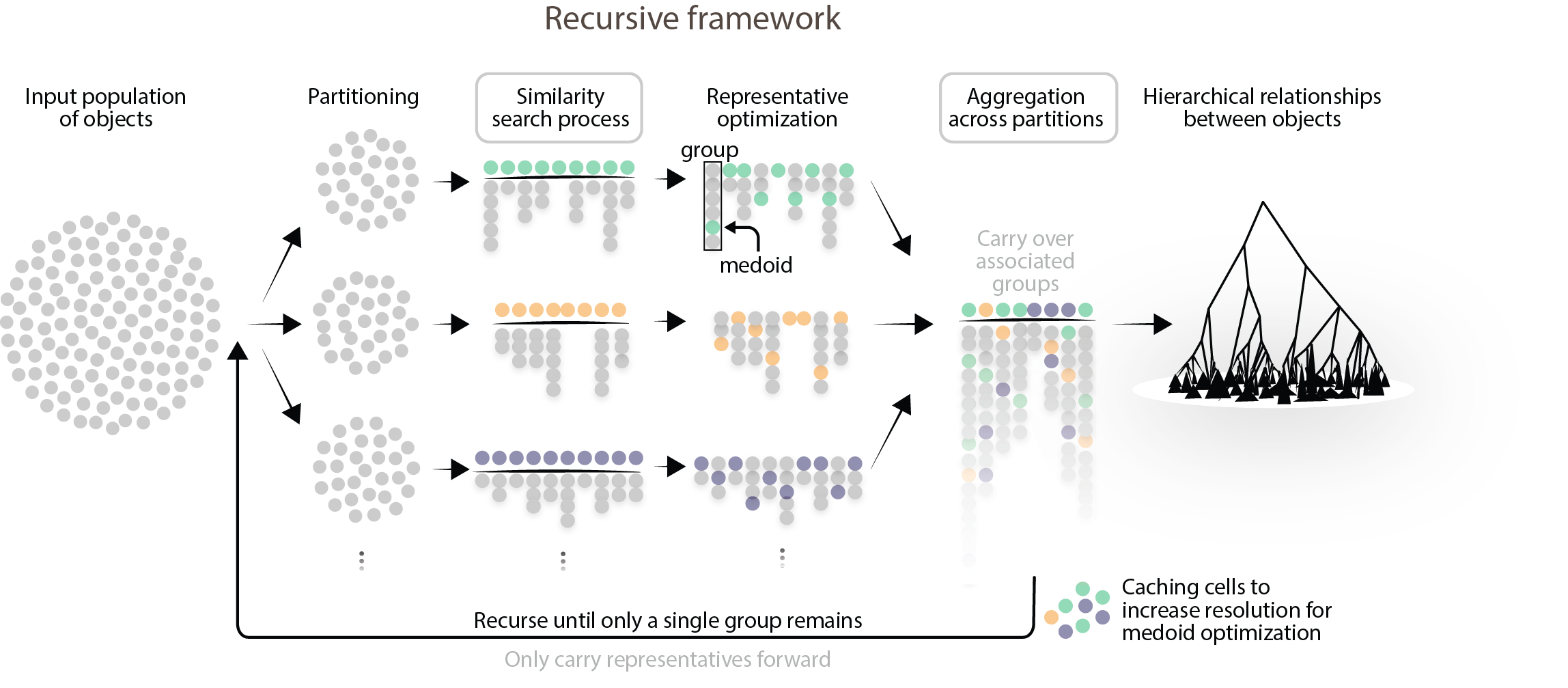
To handle datasets that exceed available memory, MILK employs a recursive, out-of-core strategy that involves partitioning the population into tractable subsets and processing them with a shared global similarity threshold. After identifying groups within each subpopulation, representatives are optimized to be the medoid of each group. All groups are then aggregated into a global list and, if tractable, an additional grouping process is performed on the representatives to resolve potential overlap across partitions. Carrying forward group representatives, this procedure can be recursively applied, which results in the progressive merging groups until a single group remains. From leaves to root, this produces a global hierarchical structure over the complete population.
Get started
For detailed use-cases of MILK, please see the tutorials.
Paper
Stay tuned…